
Building Microservices application
Microservices are an architectural and organizational approach to software development. It has some pros which are very potential for future application development. It will speed up deployment cycles, foster innovation and improve maintainability and scalability of software applications. Therefore, software is composed into small independent services that communicate over well-defined APIs and are owned by small self-contained teams.
Microservice architectures are not a completely new approach to software engineering but rather a collection and combination of various successful and proven concepts such as object-oriented methodologies, agile software development, service-oriented architectures, API-first design and Continuous Integration.
Given that the term Microservices is an umbrella. However, all Microservice architectures share some common characteristics: Here I am just reminding those in a very brief way for understanding my points later in the article. For detail, you can visit here.
- Decentralized: Microservice architectures are distributed systems with decentralized data management. They don’t rely on a unifying schema in a central database. Each Microservice has its own view on data models. Those systems are decentralized also in the way they are developed, deployed, managed and operated.
- Independent: Different components in a Microservices architecture can be changed, upgraded or replaced independently and without affecting the functioning of other dependent components.
- Do one thing well: Every component is designed around a set of capabilities and with a focus on a specific domain.
- Polyglot: Microservice architectures don’t follow a “one size fits all” approach. Teams have the freedom to choose the best platform for their specific problems. So, Microservice architectures are usually heterogeneous with regards to operating systems, programming languages, data stores, and tools.
- Black Box: Individual components of Microservices are designed as a black box, i.e. they hide the details of their complexity from other components. Any communication between services happens via well-defined APIs.
- You build it, you run it: Typically, the team responsible for building a service is also responsible for operating and maintaining it in production – this principle is also known as DevOps.
Benefits of Microservices
The distributed nature of Microservices endorse an organization of small independent teams that take ownership of their service. They are enabled to develop and deploy independently and in parallel to other teams which speeds up both development and deployment processes. The reduced complexity of the code base with which teams are working on and the reduced number of dependencies minimizes code conflicts, facilitates change, shortens test cycles and eventually improves the time to market for new features and services. Feedback from customers can be integrated much faster into upcoming releases.
The fact that small teams can act autonomously and choose the appropriate technologies, frameworks and tools for their respective problem domains is an important driver for motivation and innovation. Responsibility and accountability foster a culture of ownership for services.
Establishing a DevOps culture by merging development and operational skills in the same group eliminates possible frictions and contradicting goals. Agile processes no longer stop when it comes to deployment. Instead, the complete application life-cycle management processes from committing to releasing code can be automated. It becomes easy to try out new ideas and to roll back in case something doesn’t work. The low cost of failure creates a culture of change and innovation.
Organizing software engineering around Microservices can also improve the quality of code. The benefits of dividing software into small and well-defined modules are similar to those of object-oriented software engineering: improved reusability, composability, and maintainability of code.
Fine-grained decoupling is a best practice to build large scale systems. It’s a prerequisite for performance optimizations since it allows choosing the appropriate and optimal technologies for a specific service. Each service can be implemented with the appropriate programming languages and frameworks, leverage the optimal data persistence solution and be fine-tuned with the best performing service configurations. Properly decoupled services can be scaled horizontally and independently from each other. Vertical scaling, i.e. running the same software on bigger machines is limited by the capacity of individual servers that can incur downtime during the scaling process and it’s also very expansive. Horizontal scaling, i.e. adding more servers to the existing pool, is highly dynamic and doesn’t run into limitations of individual servers. The scaling process can be completely automated. Furthermore, the resiliency of the application can be improved since failing components can be easily and automatically replaced.
Microservice architectures also make it easier to implement failure isolation. Techniques like health-checking, caching, bulkheads or circuit breakers allow to reduce the blast radius of a failing component and to improve the overall availability of a given application.
Simple Microservice architecture on AWS
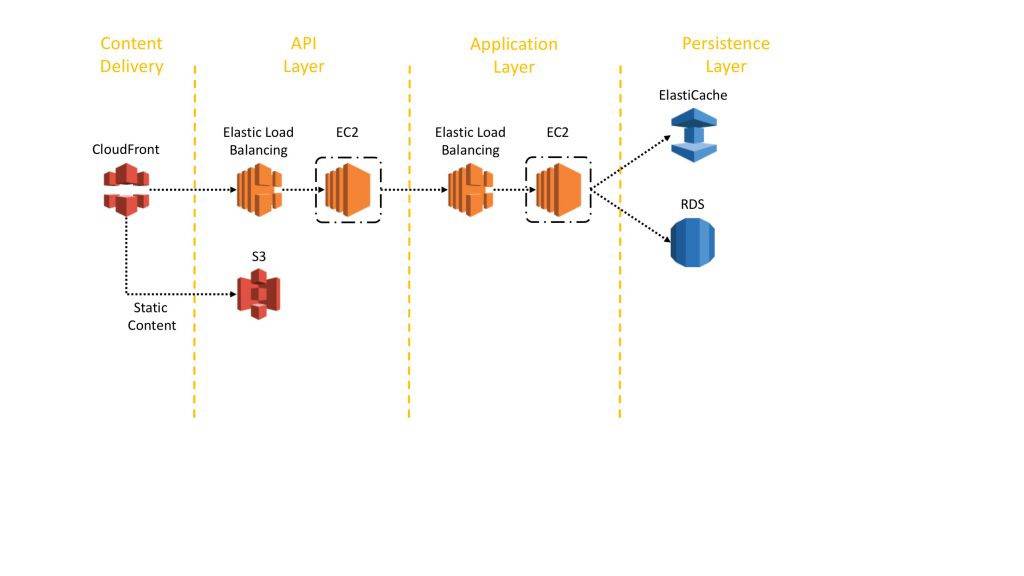
Figure 1 shows a reference architecture for a typical Microservice on AWS. The architecture is organized along four layers: Content Delivery, API Layer, Application Layer, and Persistence Layer.
The purpose of the content delivery layer is to accelerate the delivery of static and dynamic content and potentially off-load the backend servers of the API layer. Since clients of a Microservice are served from the closest edge location and get responses either from a cache or a proxy server with optimized connections to the origin, latencies can be significantly reduced. Microservices running close to each other don’t benefit from a CDN but might implement other caching mechanisms to reduce chattiness and minimize latencies.
The API layer is the central entry point for all client requests and hides the application logic behind a set of programmatic interfaces, typically an HTTP REST API. The API Layer is responsible for accepting and processing calls from clients and might implement functionality such as traffic management, request filtering, routing, caching, or authentication and authorization. Many AWS customers use Amazon Elastic Load Balancing (ELB) together with Amazon Elastic Compute Cloud (EC2) and Auto-Scaling to implement an API Layer.
The application layer implements the actual application logic. Similar, to the API Layer, it can be implemented using ELB, Auto-Scaling, and EC2.
The persistence layer centralizes the functionality needed to make data persistent. Encapsulating this functionality in a separate layer helps to keep the state out of the application layer and makes it easier to achieve horizontal scaling and fault-tolerance of the application layer.
Reducing complexity
The architecture above is already highly automated. Nevertheless, there’s still room to further reduce the operational efforts needed to run, maintain and monitor.
Architecting, continuously improving, deploying, monitoring and maintaining an API Layer can be a time-consuming task. Sometimes different versions of APIs need to be run to assure backward compatibility of all APIs for clients. Different stages (such as dev, test, prod) along the development cycle further multiply operational efforts.
Access authorization is a critical feature for all APIs, but usually complex to build and often repetitive work. When an API is published and becomes successful, the next challenge is to manage, monitor, and monetize the ecosystem of 3rd party developers utilizing the APIs.
Other important features and challenges include throttling of requests to protect the backend, caching API responses, request and response transformation or generating API definition and documentation with tools such as Swagger.
API Gateway addresses those challenges and reduces the operational complexity of the API Layer. Amazon API Gateway allows customers to create their APIs programmatically or with a few clicks in the AWS Management Console. API Gateway serves as a front door to any web-application running on Amazon EC2, on Amazon ECS, on AWS Lambda or on any on-premises environment. In a nutshell: it allows running APIs without managing servers. AWS provides several options to facilitate the deployment and further reduce the operational complexity of maintaining and running application services compared to running ELB / Autoscaling / EC2. One option is to use Elastic Beanstalk. The main idea behind Elastic Beanstalk is that developers can easily upload their code and let Elastic Beanstalk automatically handle infrastructure provisioning and code deployment. Important infrastructure characteristics such as Auto-Scaling, Load-Balancing or Monitoring are part of the service.
AWS Elastic Beanstalk supports a large variety of programming frameworks such as Java, .Net, PHP, Node.js, Python, Ruby, Go, and Docker with familiar web servers such as Apache, Nginx, Phusion Passenger, and IIS.
Another approach to reduce operational efforts for deployment is Container based deployment. Container technologies like Docker have gained a lot of popularity in the last years. This is due to a couple of benefits:
- Flexibility: containerization encourages decomposing applications into independent, fine-grained components which makes it a perfect fit for Microservice architectures.
- Efficiency: containers allow the explicit specification of resource requirements (CPU, RAM), which makes it easy to distribute containers across underlying hosts and significantly improve resource usage. Containers also have only a light performance overhead compared to virtualized servers and efficiently share resources on the underlying OS
- Speed: containers are well-defined and reusable units of work with characteristics such as immutability, explicit versioning and easy rollback, fine granularity and isolation – all characteristics that help to significantly increase developer productivity and operational efficiency.
Amazon ECS eliminates the need to install, operate and scale your own cluster management infrastructure. With simple API calls, you can launch and stop Docker-enabled applications, query the complete state of your cluster and access many familiar features like security groups, Elastic Load Balancing, EBS volumes and IAM roles.
SOA vs Microservices
The question may come to anybody’s mind that ‘Isn’t it another name of SOA?’. Well, Service-Oriented Architecture (SOA) spark up during the first few years of this century, and microservice architecture (abbreviated by some as MSA) bears a number of similarities. Traditional SOA, however, is a broader framework and can mean a wide variety of things. Some microservices fans reject the SOA tag altogether, while others consider microservices to be simply an ideal, refined form of SOA. In any event, we think there are clear enough differences to justify a distinct “microservice” concept.
The typical SOA model, for example, usually has more dependent ESBs, with microservices using faster messaging mechanisms. SOA also focuses on imperative programming, whereas microservices architecture focuses on a responsive-actor programming style. Moreover, SOA models tend to have an outsized relational database while microservices frequently use NoSQL or micro-SQL databases. But the real difference has to do with the architecture methods used to arrive at an integrated set of services in the first place.
Since everything changes in the digital world, agile development techniques that can keep up with the demands of software evolution are invaluable. Most of the practices used in microservices architecture come from developers who have created software applications for large enterprise organizations and who know that today’s end users expect dynamic yet consistent experiences across a wide range of devices. Scalable, adaptable, modular, and quickly accessible cloud-based applications are in high demand. And this has led many developers to change their approach.
Microservices: Avoiding the Monoliths
We’ve named some problems that commonly emerge; now let’s begin to look at some solutions.
How do you deploy relatively independent yet integrated services without spawning accidental monoliths? Well, suppose you have a large application, as in the sample from our Company X below, and are splitting up the codebase and teams to scale. Instead of finding an entire section of an application to split off, you can look for something on the edge of the application graph. You can tell which sections these are because nothing depends on them. In our example, the arrows pointing to Printer and Storage suggest they’re two things that can be easily removed from our main application and abstracted away. Printing either a Job or Invoice is irrelevant; a Printer just wants printable data. Turning these—Printer and Storage—into external services avoids the monoliths problem alluded to before. It also makes sense as they are used multiple times, and there’s little that can be reinvented. Use cases are well known from past experience so you can avoid accidentally removing key functionality.
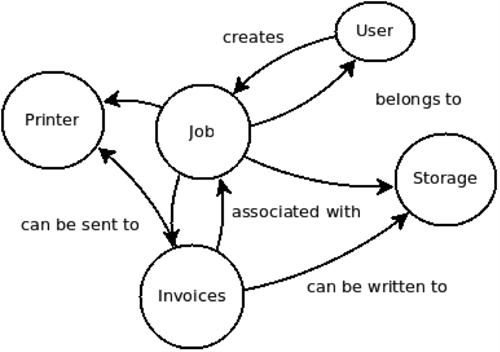
Figure 2 shows an invoicing system
Microservices Real Life example
Consider we have a software company which produces web applications and E-commerce sites for clients. Most of the web applications require log-in functionality. We can easily separate this module out as it can work independently (we can make this robust that way) and implement this log-in function as a Microservice. Then we can keep it in the API-Gateway of web-service provider (Like Amazon web service) and can access that microservice for all the web application we need (existing and new development). Log-in Microservice will maintain its own database by logging the tenant-id or app-id for which it served its service along with required information. We can scale it up by keeping this in different zonal API-Gateway as well to serve faster. The benefit is, we don’t need to re-implement or copy early implementation of log-in module for each application. We will just use this service for any application. If any issue or bug found or additional extension of implementation is needed, we will do it in the Microservice (only one place) and it will work for all. Similarly, we can consider online payment module for all E-commerce sites. We can separate this module and build a Microservice for this like E-Pay Microservice and place it behind API-Gateway of web-service provider and use it for all the E-commerce applications we have. We always have to keep in mind that, it is ‘Micro’ service and it supposed to serve only one purpose or goal. So, if a module become bulky or complex it’s better to split that and make several independent Microservices and use those accordingly. It is also possible that microservices can communicate each other. They can individually serve one purpose but combinedly can serve a big goal as well. It’s completely our choice whether we will use these one after another in our application to achieve that goal or make a Microservice that combines those smaller Microservices and produce that output. Well, I personally favor the first choice so that they remain de-coupled and organizing and manipulating power remains in my hand. To clarify more about splitting a complex Microservice we can again consider the Log-in Microservice as just an example. Well, Log-in can be many types like: user/password, with g-mail/fb/twitter/Office365 login. We can make separate log-in Microservices for each type (like FBLoginMicroservice, Office365LoginMicroservice etc) and can use any one of them at a time as per user tries a particular type to login. Similarly, we can separate out E-Pay Microservices in smaller Microservices for different types of credit cards like VISA/AMEX/MASTER etc. The bottom line is to thinner our application in all aspects like source code size, resource utilization etc to get maximum efficiency possible so that users gets very quick responses from the applications.
Microservice Pros and Cons
Microservices are not a silver bullet and by implementing them you will expose communication, teamwork and other problems that may have been previously implicit but are now forced out into the open. But API Gateways in Microservices can greatly reduce build and qa time and effort.
One common issue involves sharing schema/validation logic across services. What X requires in order to consider some data valid doesn’t always apply to Y, if Y has different needs. The best recommendation is to apply versioning and distribute schema in shared libraries. Changes to libraries then become discussions between teams. Also with strong versioning brings dependencies which can cause more overhead. The best practice to overcome this is planning around backwards compatibility, and accepting regression tests from external services/teams. These prompt you to have a conversation before you disrupt someone else’s business process, not after.
As always, whether or not microservice architecture is right for you depends on your requirements, because they all have their pros and cons. Here’s a quick rundown of some of the good and bad:
Pros
• Microservice architecture gives developers the freedom to independently develop and deploy services
• A microservice can be developed by a fairly small team
• Code for different services can be written in different languages.
• Easy integration and automatic deployment (using open-source continuous integration tools such as Jenkins, Hudson, etc.)
• Easy to understand and modify for developers thus can help a new team member become productive quickly
• The developers can make use of the latest technologies
• The code is organized around business capabilities
• Starts the web container more quickly so the deployment is also faster
• When change is required in a certain part of the application, only the related service can be modified and redeployed—no need to modify and redeploy the entire application
• Better fault isolation: if one microservice fails, the other will continue to work
• Easy to scale and integrate with third-party services
• No long-term commitment to technology stack
Cons
• Due to distributed deployment, testing can become complicated and tedious
• Increasing number of services can result in information barriers
• The architecture brings additional complexity as the developers have to mitigate fault tolerance, network latency and deal with a variety of message formats as well as load balancing
• Being a distributed system, it can result in duplication of effort
• When number of services increases, integration and managing whole products can become complicated
• In addition to several complexities of monolithic architecture, the developers have to deal with the additional complexity of a distributed system
• Developers have to put additional effort into implementing the mechanism of communication between the services
• Handling use cases that span more than one service without using distributed transactions is not only tough but also requires communication and cooperation between different teams
• The architecture usually results in increased memory consumption
• Partitioning the application into microservices is very much an art
Conclusion
Microservice architectures are a distributed approach to overcome the shortcomings of traditional monolithic architectures. While Microservices help to scale applications and organizations whilst improving cycle times, they also come with a couple of challenges that may cause additional architectural complexity and operational burden.
AWS offers a large portfolio of managed services that help product teams to build Microservice architectures and minimize architectural and operational complexity. So it seems that, it may become the potential software architecture in short future specially for Web and Mobile applications.
Links and literature
[1] https://en.wikipedia.org/wiki/Conway%27s_law [2] http://swagger.io/ [3] https://github.com/awslabs/chalice [4] https://serverless.com/ [5] https://aws.amazon.com/blogs/compute/service-discovery-via-consul-with-amazon-ecs/ [6] https://github.com/spring-cloud/spring-cloud-sleuth [7] http://zipkin.io/ [8] https://smartbear.com/learn/api-design/what-are-microservices/
Add a Comment